除了上一篇提到的缺失值、空值資料以外,重複值以及離群值的資料也需要一併處理,資料如果有重複,會加重對結果的影響,若是資料有離群值,有可能是因為數據記錄錯誤或是誤填導致,若不處理,很可能扭曲實驗的結果,得到非最佳解。在 Azure Machine Learning Studio 中,可以使用 Remove Duplicate Rows 處理重複值,使用 Clip Values 處理離群值。
位置:Data Transformation / Manipulation / Remove Duplicate Rows
(1) 新增"Remove Duplicate Rows"移除重複值,將資料集的輸出接至 Remove Duplicate Rows,選擇要判斷的欄位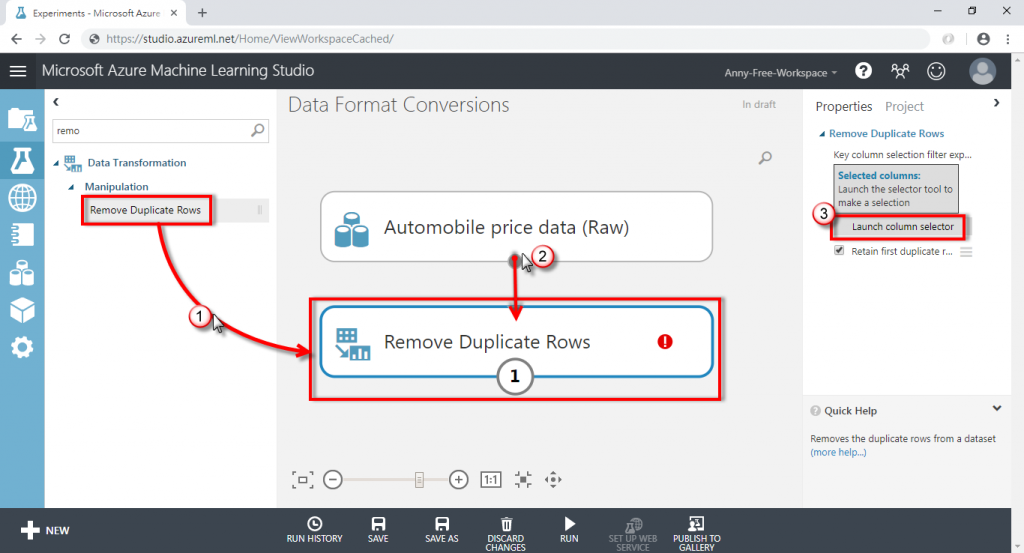
(2) 可以選擇單欄位,也可以選擇多欄位,若選擇多欄位,選擇的欄位都有符合重複條件才會移除,這邊以全部欄位為例,也就是兩筆資料完全一樣才會移除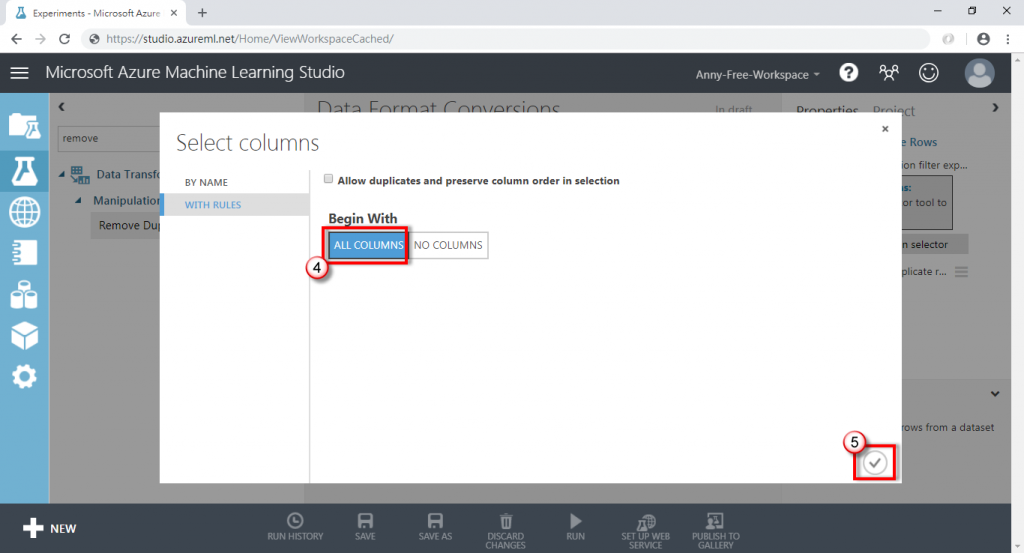
(3) 點選執行,即可移除重複值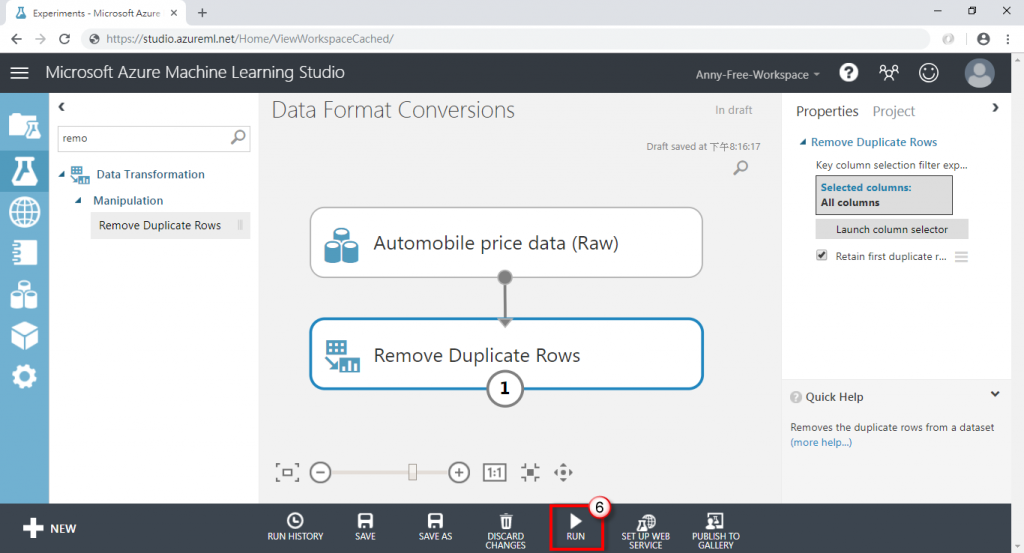
位置:Data Transformation / Scale and Reduce / Clip Values
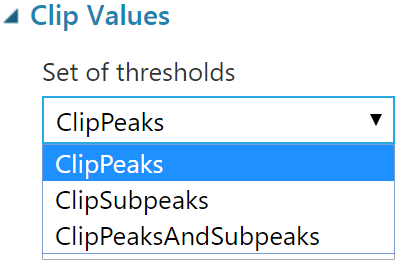
針對離群值處理,可以使用 Clip Values 修改資料,可選擇以下 3 種修改對象:
1. ClipPeaks 修改或替換超過指定上限邊界的值
2. ClipSubpeaks 修改或替換低於指定下限邊界的值
3. ClipPeaksAndSubpeaks 同時修改或替換超過指定上限、低於指定下限邊界的值
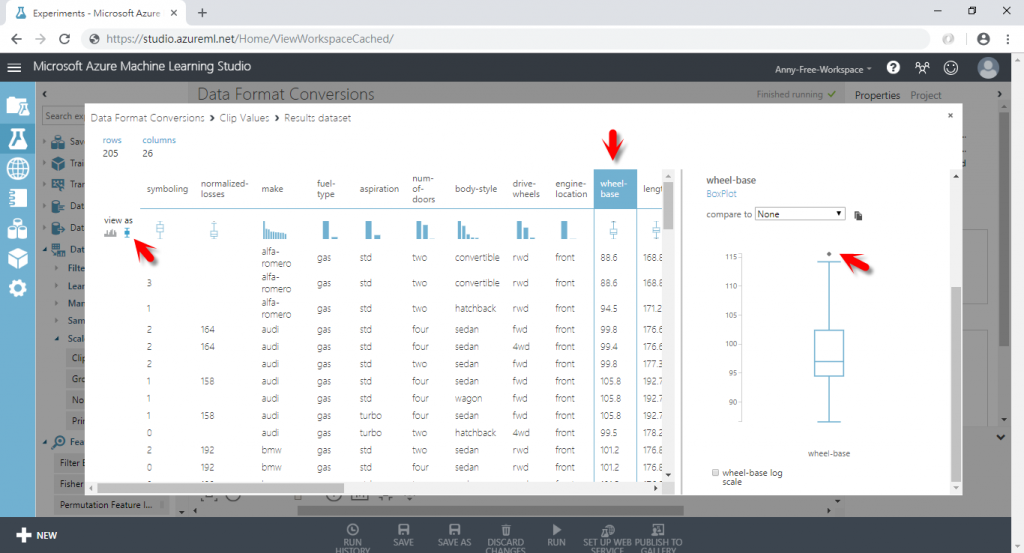
(1) 離群值不好用人工瀏覽資料的方式判斷出來,可以透過資料集視覺化工具來找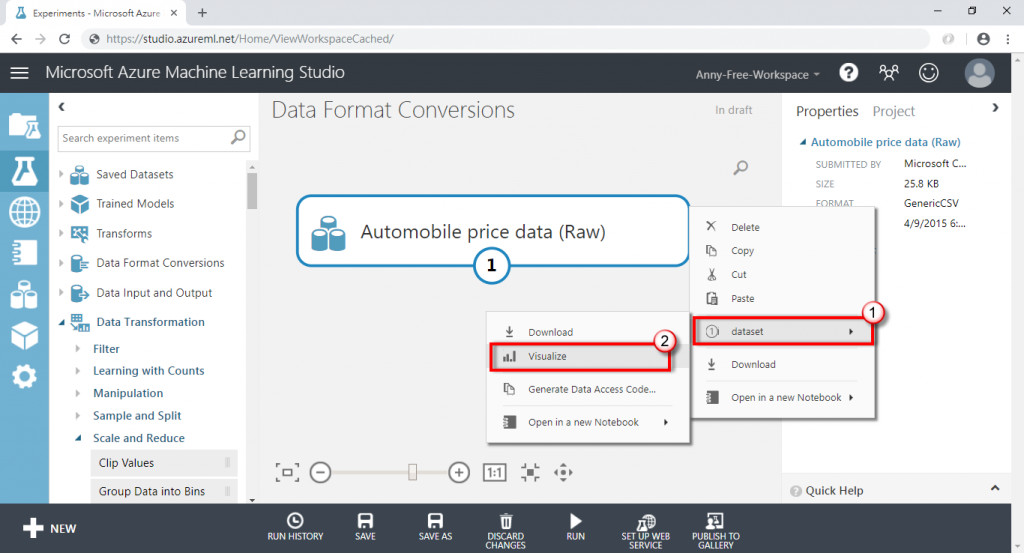
(2) 先將左邊的檢視方式調整為 BoxPlot 箱型圖,比較好觀察該欄位資料是否有離群值,以下方的 wheel-base 輪軸欄位為例,在箱型圖上方超過 115 的幾筆資料即為離群值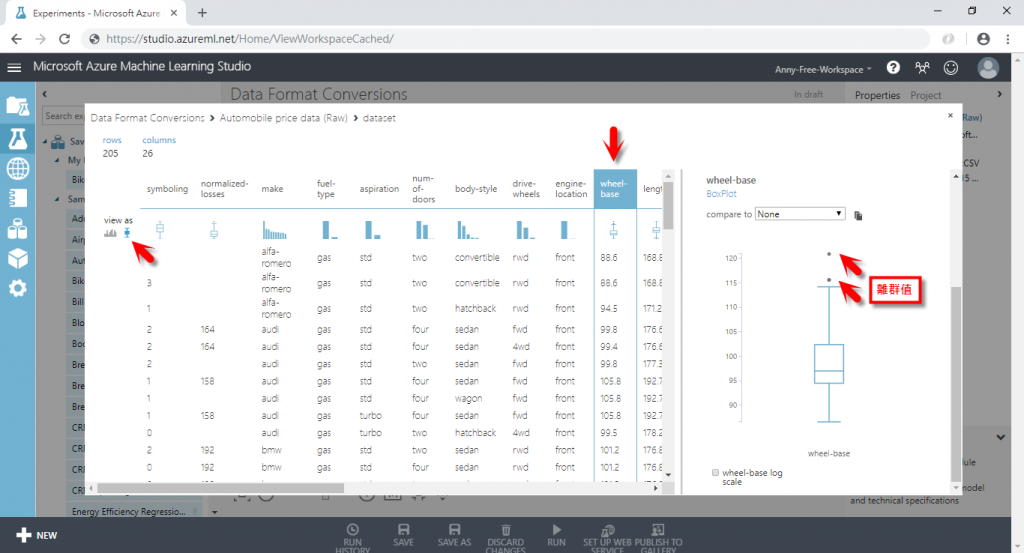
(3) 新增"Clip Values"修剪值,將資料集的輸出接至 Clip Values,選擇要處理的離群值"ClipPeaks",選擇要處理的欄位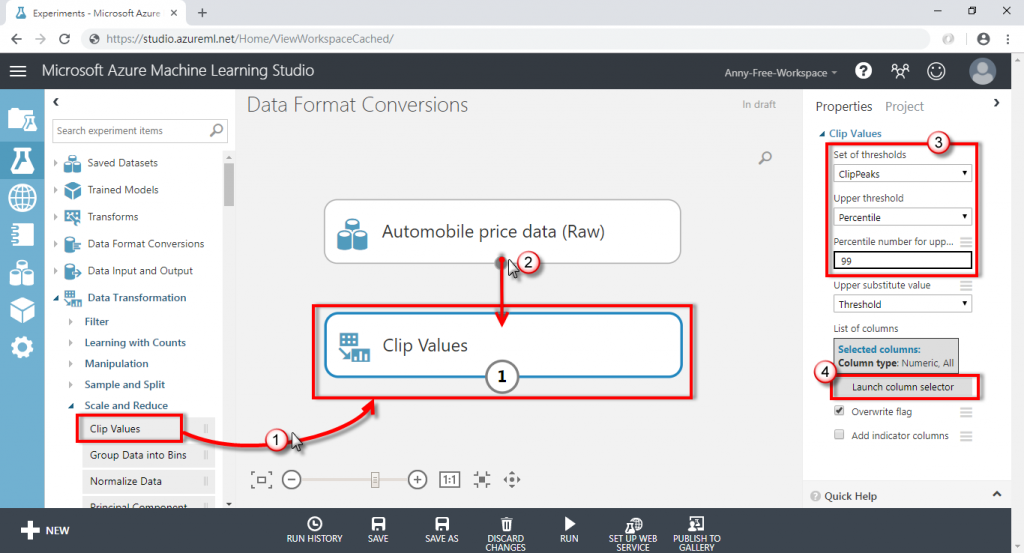
(4) 選擇有離群值的 wheel-base 輪軸欄位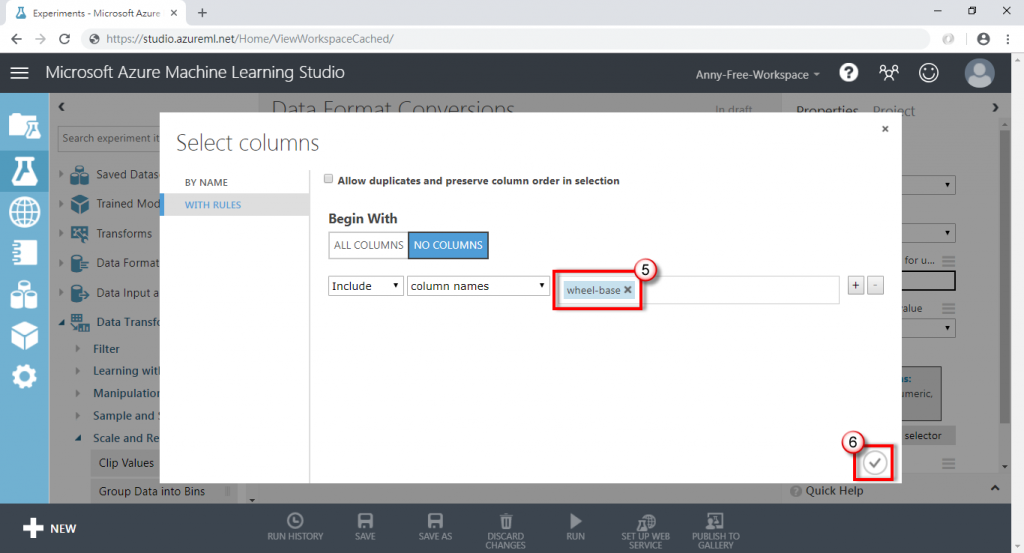
(5) 執行後,查看處理結果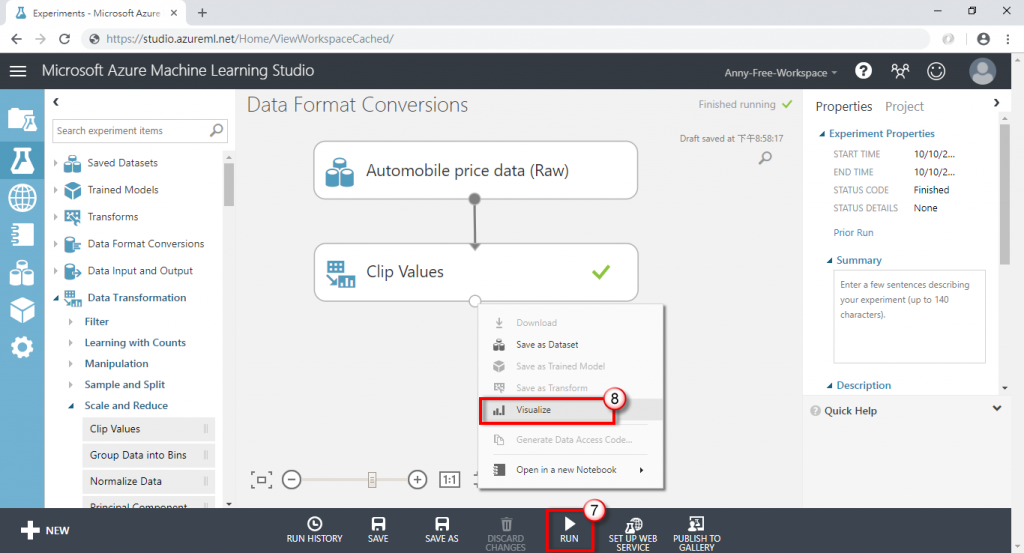
(6) 可以看到超過上限的離群值資料被修改了,不會太偏離其他的資料